MD5,RSA,SHA256,DES
MD5算法原理
MD5本质上是一个哈希函数。但是MD5具有雪崩效应(Avalanche Effect)、抗碰撞性等的性质。为了保证这些性质,MD5的算法设计比较复杂。下面就来说明MD5算法的原理。
MD5算法的处理步骤可以概括为两步:数据填充、分组循环变换,拼接输出。
数据填充
MD5算法的第二步“分组循环变换”是以512位为一个分组进行处理的。因此,需要把数据填充成长度为512位的倍数。具体填充步骤如下:
1、先填充一个“1”,后面加上k个“0”。其中k是满足(n+1+k) mod 512 = 448的最小正整数。
第一步,对原始信息进行填充,填充之后,要求信息的长度对512取余等于448。填充的规则如下:假设原始信息长度为b bit,那么在信息的b+1 bit位填充1,剩余的位填充0,直到信息长度对512取余为448。
这里有一点需要注意,如果原始信息长度对512取余正好等于448,这种情况仍然要进行填充,很明显,在这时我们要填充的信息长度是512位,直到信息长度对512取余再次等于448。所以,填充的位数最少为1,最大为512。
代码实现
1 | message.append(0x80) |
2、第二步,填充信息长度,我们需要把原始信息长度转换成以bit为单位,然后在第一步操作的结果后面填充64bit的数据表示原始信息长度。第一步对原始信息进行填充之后,信息长度对512取余结果为448,这里再填充64bit的长度信息,整个信息恰好可以被512整除。其实从后续过程可以看到,计算MD5时,是将信息分为若干个分组进行处理的,每个信息分组的长度是512bit。则最高位字节位于字节数组的末尾,在这个结果后面附加一个以64位二进制表示的填充前信息长度,追加64位的数据长度(bit为单位,小端序存放)
填充完的数据大概长这样:

代码实现
1 | message += orig_len_in_bits.to_bytes(8, byteorder='little') |
分组循环变换,拼接输出
先初始化A、B、C、D四个[32位常数,然后将填充完成后的数据划分成一个个512位的分组,依次进入循环变换。A、B、C、D也参与到循环变换中。数据分组进去变换的时候,大概走这么个流程:
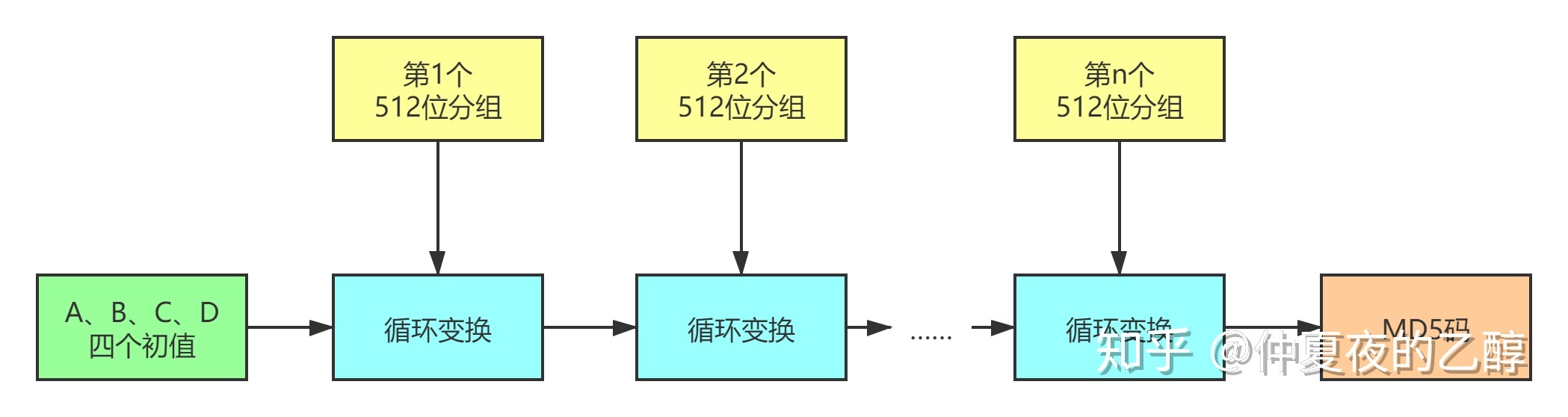 分组循环变换示意图
分组循环变换示意图
循环变换是整个MD5算法最核心,也是最复杂的部分。一个512位分组的数据被进一步划分为16个32位的子分组,对每个子分组进行下图所示的变换:
 一个子分
一个子分
组进行的变换
上面只是画出了一个子分组进行的变换。下面对图中的元素进行说明:
- F函数表示非线性变换,加号表示加法运算。
- 常数AC的值在每一次变换中都不一样,表达式为
,i表示第i次变换。
- 左移位数S有规律地周期性变化。
数据的16个子分组都参与到上图所示的变换,顺序不定。当16个子分组处理完成时,我们就说完成了一轮循环变换。MD5的一个数据分组一共需要进行四轮的循环变换。将四轮循环变换后得到的A、B、C、D的值分别和原来的值相加,就是A、B、C、D进行循环变换后的结果。
循环变换的循环里的具体流程
B = b+((a+F(b,c,d)+Mj+Ki)<<<s)
新A = 原d新B = b+((a+F(b,c,d)+Mj+Ki)<<<s)新C = 原b新D = 原c
计算F(b,c,d)
先A,B,C,D四个初始值
1 | init_values = [0x67452301, 0xefcdab89, 0x98badcfe, 0x10325476] |
最终得到的结果是这样的
MJ:数据子分组
Ki:也即常数AC
F函数:由位运算构成的非线性变换
新A = 原d
新B = b+((a+F(b,c,d)+Mj+Ki)<<<s)
新C = 原b
新D = 原c
分组循环步骤
首先是F函数的规定的非线性变换,每一轮循环变换用到的F函数不一样。
F(X, Y, Z) =(X&Y) | ((~X) & Z)
G(X, Y, Z) =(X&Z) | (Y & (~Z))
H(X, Y, Z) =X^Y^Z
I(X, Y, Z)=Y^(X|(~Z))
在主循环下面64次子循环中,F、G、H、I 交替使用,第一个16次使用F,第二个16次使用G,第三个16次使用H,第四个16次使用I。
1 | functions = 16*[lambda b, c, d: (b & c) | (~b & d)] + \ |
计算Mj
然后是数据子分组
1 | index_functions = 16*[lambda i: i] + \ |
接着计算a+F(b,c,d)+Mj+Ki
计算KI
KI也即常数AC,又叫正弦函数,计算出他的表
1 | #正弦函数表 |
也即如下常数
1 | 正弦函数表(sine table)K:sine table共有64个常量数值,每个数值长度32bits,图中K_i就是就是这个sine table。 |
计算(a+F(b,c,d)+Mj+Ki)<<<s
然后把他们相加
1 | to_rotate = a + f + constants[i] + int.from_bytes(chunk[4*g:4*g+4], byteorder='little') |
然后再循环左移,循环每次左移的位数表如下
1 | rotate_amounts = [7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, |
MJ:数据子分组
Ki:也即常数AC
F函数:由位运算构成的非线性变换
新A = 原d
新B = b+((a+F(b,c,d)+Mj+Ki)<<<s)
新C = 原b
新D = 原c
具体轮次如下
1 | 这四轮(共64步)是: |
以十六进制的形式拼接
将经过若干次循环变换后的A、B、C、D以十六进制的形式拼接起来,就是传说中的MD5码了。
代码实现
最后实现代码如下
1 | #!/usr/bin/python3 |
注释
1 | #!/usr/bin/python3 |
RSA算法原理
RSA是一种公钥密码算法,其影响力我就不多说了,算法原理网上多的是,看了几篇,还是觉得阮一峰写的好懂。
可阅读下面文章来了解RSA算法。
RSA算法原理(一)
RSA算法原理(二)
第一步,随机选择两个不相等的质数p和q。
爱丽丝选择了61和53。(实际应用中,这两个质数越大,就越难破解。)
第二步,计算p和q的乘积n。
爱丽丝就把61和53相乘。
n = 61×53 = 3233
n的长度就是密钥长度。3233写成二进制是110010100001,一共有12位,所以这个密钥就是12位。实际应用中,RSA密钥一般是1024位,重要场合则为2048位。
第三步,计算n的欧拉函数φ(n)。
根据公式:
φ(n) = (p-1)(q-1)
爱丽丝算出φ(3233)等于60×52,即3120。
第四步,随机选择一个整数e,条件是1< e < φ(n),且e与φ(n) 互质。
爱丽丝就在1到3120之间,随机选择了17。(实际应用中,常常选择65537。)
第五步,计算e对于φ(n)的模反元素d。
所谓“模反元素”就是指有一个整数d,可以使得ed被φ(n)除的余数为1。
ed ≡ 1 (mod φ(n))
这个式子等价于
ed - 1 = kφ(n)
于是,找到模反元素d,实质上就是对下面这个二元一次方程求解。
ex + φ(n)y = 1
已知 e=17, φ(n)=3120,
17x + 3120y = 1
这个方程可以用“扩展欧几里得算法”求解,此处省略具体过程。总之,爱丽丝算出一组整数解为 (x,y)=(2753,-15),即 d=2753。
至此所有计算完成。
第六步,将n和e封装成公钥,n和d封装成私钥。
在爱丽丝的例子中,n=3233,e=17,d=2753,所以公钥就是 (3233,17),私钥就是(3233, 2753)。
实际应用中,公钥和私钥的数据都采用ASN.1格式表达(实例)。
七、RSA算法的可靠性
回顾上面的密钥生成步骤,一共出现六个数字:
p
q
n
φ(n)
e
d
这六个数字之中,公钥用到了两个(n和e),其余四个数字都是不公开的。其中最关键的是d,因为n和d组成了私钥,一旦d泄漏,就等于私钥泄漏。
那么,有无可能在已知n和e的情况下,推导出d?
(1)ed≡1 (mod φ(n))。只有知道e和φ(n),才能算出d。
(2)φ(n)=(p-1)(q-1)。只有知道p和q,才能算出φ(n)。
(3)n=pq。只有将n因数分解,才能算出p和q。
结论:如果n可以被因数分解,d就可以算出,也就意味着私钥被破解。
可是,大整数的因数分解,是一件非常困难的事情。目前,除了暴力破解,还没有发现别的有效方法。维基百科这样写道:
“对极大整数做因数分解的难度决定了RSA算法的可靠性。换言之,对一极大整数做因数分解愈困难,RSA算法愈可靠。
假如有人找到一种快速因数分解的算法,那么RSA的可靠性就会极度下降。但找到这样的算法的可能性是非常小的。今天只有短的RSA密钥才可能被暴力破解。到2008年为止,世界上还没有任何可靠的攻击RSA算法的方式。
只要密钥长度足够长,用RSA加密的信息实际上是不能被解破的。”
举例来说,你可以对3233进行因数分解(61×53),但是你没法对下面这个整数进行因数分解。
12301866845301177551304949
58384962720772853569595334
79219732245215172640050726
36575187452021997864693899
56474942774063845925192557
32630345373154826850791702
61221429134616704292143116
02221240479274737794080665
351419597459856902143413
它等于这样两个质数的乘积:
33478071698956898786044169
84821269081770479498371376
85689124313889828837938780
02287614711652531743087737
814467999489
×
36746043666799590428244633
79962795263227915816434308
76426760322838157396665112
79233373417143396810270092
798736308917
事实上,这大概是人类已经分解的最大整数(232个十进制位,768个二进制位)。比它更大的因数分解,还没有被报道过,因此目前被破解的最长RSA密钥就是768位。
八、加密和解密
有了公钥和密钥,就能进行加密和解密了。
(1)加密要用公钥 (n,e)
假设鲍勃要向爱丽丝发送加密信息m,他就要用爱丽丝的公钥 (n,e) 对m进行加密。这里需要注意,m必须是整数(字符串可以取ascii值或unicode值),且m必须小于n。
所谓”加密”,就是算出下式的c:
me ≡ c (mod n)
爱丽丝的公钥是 (3233, 17),鲍勃的m假设是65,那么可以算出下面的等式:
6517 ≡ 2790 (mod 3233)
于是,c等于2790,鲍勃就把2790发给了爱丽丝。
(2)解密要用私钥(n,d)
爱丽丝拿到鲍勃发来的2790以后,就用自己的私钥(3233, 2753) 进行解密。可以证明,下面的等式一定成立:
cd ≡ m (mod n)
也就是说,c的d次方除以n的余数为m。现在,c等于2790,私钥是(3233, 2753),那么,爱丽丝算出
27902753 ≡ 65 (mod 3233)
因此,爱丽丝知道了鲍勃加密前的原文就是65。
至此,”加密–解密”的整个过程全部完成。
我们可以看到,如果不知道d,就没有办法从c求出m。而前面已经说过,要知道d就必须分解n,这是极难做到的,所以RSA算法保证了通信安全。
你可能会问,公钥(n,e) 只能加密小于n的整数m,那么如果要加密大于n的整数,该怎么办?有两种解决方法:一种是把长信息分割成若干段短消息,每段分别加密;另一种是先选择一种”对称性加密算法”(比如DES),用这种算法的密钥加密信息,再用RSA公钥加密DES密钥。
九、私钥解密的证明
最后,我们来证明,为什么用私钥解密,一定可以正确地得到m。也就是证明下面这个式子:
cd ≡ m (mod n)
因为,根据加密规则
me ≡ c (mod n)
于是,c可以写成下面的形式:
c = me - kn
将c代入要我们要证明的那个解密规则:
(me - kn)d ≡ m (mod n)
它等同于求证
med ≡ m (mod n)
由于
ed ≡ 1 (mod φ(n))
所以
ed = hφ(n)+1
将ed代入:
mhφ(n)+1 ≡ m (mod n)
接下来,分成两种情况证明上面这个式子。
(1)m与n互质。
根据欧拉定理,此时
mφ(n) ≡ 1 (mod n)
得到
(mφ(n))h × m ≡ m (mod n)
原式得到证明。
(2)m与n不是互质关系。
此时,由于n等于质数p和q的乘积,所以m必然等于kp或kq。
以 m = kp为例,考虑到这时k与q必然互质,则根据欧拉定理,下面的式子成立:
(kp)q-1 ≡ 1 (mod q)
进一步得到
[(kp)q-1]h(p-1) × kp ≡ kp (mod q)
即
(kp)ed ≡ kp (mod q)
将它改写成下面的等式
(kp)ed = tq + kp
这时t必然能被p整除,即 t=t’p
(kp)ed = t’pq + kp
因为 m=kp,n=pq,所以
med ≡ m (mod n)
原式得到证明。
现在思考一下,我们还有两个问题。
- 怎么产生一个大素数
- 怎么实现大数的模幂运算
接下来我们就来一一解决这两个问题。
https://saucer-man.com/cipher/83.html
1.实现大数的模幂运算
为什么先解决这个呢,因为大素数的产生需要用到这个函数,所以我们首先实现大数的模幂运算。
先来考虑一个简单的问题,怎么计算 3 ^ 13 (mod 9)?
那还用想?直接用计算机算 3 ^ 13 不就好了,但是如果是33333 ^ 1333333333呢,这计算机得算到什么时候,所以我们得想个法子减少计算量。
这里要利用到我们所熟知的两个公式
(a \* b) (mod n) = a (mod n) \* b (mod n)
a ^ (b+c) = a^b \* a^c
那么上面的13 = 1*2^3 + 1*2^2 + 0*2^1 + 1*2^0。3^13就可以转化为3^(1*2^3) * 3^(1*2^2) * 3^(0*2^1) * 3^(1*2^0)
到这里我们就清楚了。我们可以先算3^(1*2^0) (mod 9),假设其结果为res。然后再算3^(0*2^1) (mod 9), 那么这个就等于0 * res^2 (mod 9),所以我们只要将上一步的数值乘以该二进制数的系数再平方。一直类推下去, 然后把每一步得到的结果res乘起来模上9,就是 3^(1*2^3) * 3^(1*2^2) * 3^(0*2^1) * 3^(1*2^0) (mod 9)
对于所有的a^b (mod n)都可以这么做,把b分解为二进制。这种快速模幂运算也叫蒙哥马利运算。
看代码来理解更方便:
1 | def pow_mod(p, q, n): |
2.产生一个大素数
我们解决的思路是先产生一个大数,然后再判断其是不是素数。
产生大数很简单,直接使用rand函数来产生每一位数字,然后拼接起来不就好了吗。
直接看代码即可
1 | def probin(w): |
通过以上代码我们产生了一个非常大的奇数,但是我们怎么来检验其是否为素数呢,这里使用了非常通用的miller rabin算法来检验。
其算法原理是利用了费马定理的结论:
- 费马小定理:对于素数p和任意整数a,有a^(p−1) = 1 (mod p)
Miller Rabin素数判定,在费马定理的基础上增加了二次判定:
- 如果p是素数,则 x^2=1 (mod p)的解为x=1或x=p−1(mod p)
根据费马定理,如果p为素数,正好有 a^(p−1) = 1 (mod p),那么x^((p-1)/2) = 1 或者 p-1。如果x^((p-1)/2) = 1,那么x^((p-1)/2/2) = 1 或者p-1…..
直到(p-1)/2/2/2/2…不能再继续除2了为止(再除2就会产生小数,这里我们所有的数字都得是整数。)
因为a^(p−1) = 1 (mod p)是必然存在的,那么必然会有一个解。如果直到算到(p-1)除2除不了了也没有结果,那么p就不是素数。
对于任意两个素数都需要符合费马定理,且满足二次定理,即对于任意的a, a^(p−1) = 1 (mod p)有解。
那么满足上述两个条件是否一定证明其为素数,也不是,这只是一个必要但不充分条件,但是科学证明,当取任意多个a都符合上述条件的时候,我们就可以判断其为素数(误判的概率很小)。
接下来我们就来判断一个大数是否满足费马定理和二次定理。
1 | def prime_miller_rabin(a, n): # 随机生成a, 检测n是否为素数 |
接下来我们随机产生几个a,来检验其是否都满足费马定理和二次定理。
1 | def prime_test(n, k): # 产生k个a |
然后就到了产生素数的函数了。这里我们使用while循环,什么时候产生素数成功了什么时候退出。
1 | def get_prime(bit): |
上述代码很直观,直接产生一个大奇数来判断,如果不是素数,则把大素数加2再进行判断。依次类推,加上50次以后还不是素数的化则重新生成一个大奇数。
遍历 [奇数, 奇数+100]的范围应该会有一个素数,这样也提高了成功率。
今天上课听老师说还有一种方法来避免盲目的产生大数,设产生大数为A, 如果A对7取模是5,那么A+5、A+12、A+19、A+26都是7的倍数,也就不是素数了,这样就可以排除这些数字。同样的方法对100以内的数字取模,然后排除掉A后的很多数字,下一次就可以直接取没有被排除的数字。这样就需要生成一个数组来保存被排除的数。
其实思路差不多,我的代码是直接加2,实现起来简单一点,如果不需要产生很多很多的大素数,效果应该也不差。
接下来就是RSA了,我们还得取一个e,这里的e是加密用的,如果实现了模幂运算,那么你就会明白e的取值直接影响了加密的速度,一般e的取值都是比较小,几位或者十几位二进制,而且二进制里的1要少(加快模幂运算速度,思考一下为什么)。
e还需要和(p-1)*(q-1)互素,因为要求模幂,这里我们暂定其为65537(二进制为10000000000000001)。如果和(p-1)*(q-1)不互素,那我们就换一个。所以这里还要有个函数来检测e和(p-1)*(q-1)是否互素。
1 | def gcd(a,b): |
代码很简单,利用了欧几里得算法求公约数,公约数为1不就互素了吗。
到现在我们已经确定e和p,q,加密看起来so easy了。
但是解密还要求出解密密钥 d = e ^(-1) (mod (p-1)*(q-1))。这里也就是求e对于(p-1)*(q-1)的逆。
模逆运算
1 | def mod_1(x, n): |
解密密钥d也算出来了
sha256
https://zhuanlan.zhihu.com/p/340917911
关于区块链
http://www.ruanyifeng.com/blog/2017/12/blockchain-tutorial.html
一、准备需要二进制字节(Byte)组,如字符’abc’
1、’abc’转换成Byte
1 | >>> 'abc'.encode('utf8') |
2、补位为64Byte(即512Bit)
2.1补位64Byte(512Bit)规范
a+b+c+1+0+abc位数

1 | >>> bin('a'.encode('utf8')[0]) |
a+b+c+1+0+abc位数 : 1100001+01100010+01100011+1+0……+00011000=512 Bit
另外几种补位方式
binaries = binaries[‘xx1’, ‘xx2’,’xx3’]
M = binaries [n],即是binaries[0,1,2]=64Byte, 在后面binaries[n]上补位
55 < M <56时:补位 M = M+1+len(M)
56 < M <64时:补位 M = M+1,再附加M = binaries[n+1] = 0+len(M)
binaries % 64 = 0 时:补位,附加M = binaries[n+1] = 1+0+len(M)
2.2换成Byte(二进制字节)
1 Byte =8 Bit 即 b’\xff’ = 0b11111111 = 0xFF
1 | >>> (0xFF).to_bytes(1, byteorder='big') |
a+b+c+1+0+abc位数 注:1跟随在abc后面的首位,所以是10000000
b’abc’+b’\x80’+b’\x00’……+b’\x00\x00\x00\x00\x00\x00\x00\x18’=64 Byte
1 | >>> (0b10000000).to_bytes(1, byteorder='big') |
2.3验证补位
abc补位之后的16进制是上面这样
1 | binaries = 'abc'.encode('utf8') |
二、SHA256算法
1、初始值


1 | H = [ |
2、初始化,W为64个空列表,并按要求载入数据

2.1初始化W为64个空列表
1 | W = [0] * 64 |
2.2将二进制字节(Byte)组(binaries)分割成16个4Byte(32bit),并转换16进制数字,存放到W[0:16]
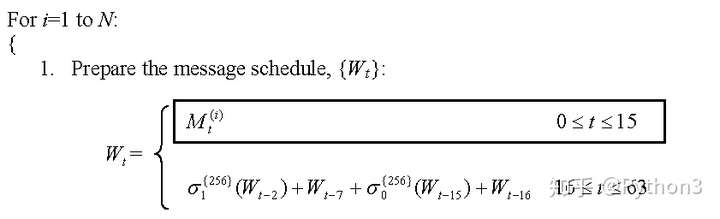
1 | W = [0] * 64 |
D:\Python\Project02\SHA>SHA256TEST.py
[1633837952, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 24]
2.3按公式要求,放入W[16:64]
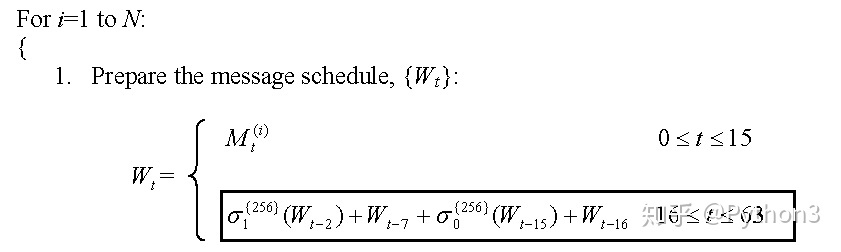
公式分解图如下,名词定义解释(DEFINITIONS)见最后面附录

先来第一项S1
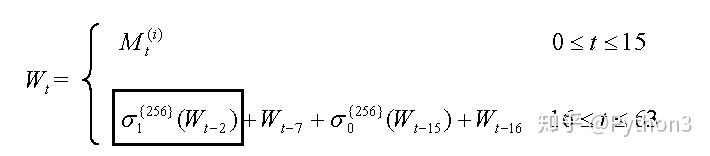
第一项的公式S1分解如下
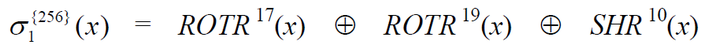
1 | S1 = ROTR(W[t - 2], 17) ^ ROTR(W[t - 2], 19) ^ (W[t - 2]>>10) |
第二项Wt-7
1 | W[t - 7] |
第三项S0

公式分解

1 | S0 = ROTR (W[t - 15], 7) ^ ROTR (W[t - 15], 18) ^ (W[t - 15]>>3) |
第四项Wt-16
1 | W[t-16] |
完全公式
1 | W[t] = (S1+W[t-7]+S0+W[t-16]) |
ROTR函数定

ROTR(x) = (x>>n) | (x<<w-n)
1 | def ROTR(x, n): |
全部整合起来
1 | for t in range(16, 64): |
压缩为8位 & 0xFFFFFFFF 为什么要进行压缩为8位?因为运算的时候超过8位16进制数字了 压缩的目的是去掉8位前多余的数值
1 | >>> hex(0xa54ff53a + 0xb85e2ce9) |
D:\Python\Project02\SHA>SHA256TEST.py
[1633837952, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 24, 1633837952, 983040, 2108187653, 1610613702, 1050508152, 25426944, 316456923, 3806512014, 3357629466, 3073800610, 3854317833, 845560923, 2636160359, 3968280267, 1881225380, 3552024379, 2482346367, 996719219, 2952069057, 4043988066, 176896406, 1924104970, 2483675 966, 610538786, 2672279444, 4037431130, 1042573945, 657669027, 206005234, 2215296807, 2049510749, 106709978, 4215179723, 3430291419, 3118885940, 2845390439, 222 6839261, 3256115900, 344409900, 2987358873, 4015503821, 3957764664, 2682456414, 2025622859, 2755645205, 1720397816, 4004225740, 313650667]
3、各个赋值为H

1 | a = H[0] |
4、开始计算SHA256,公式如下

S1公式分解
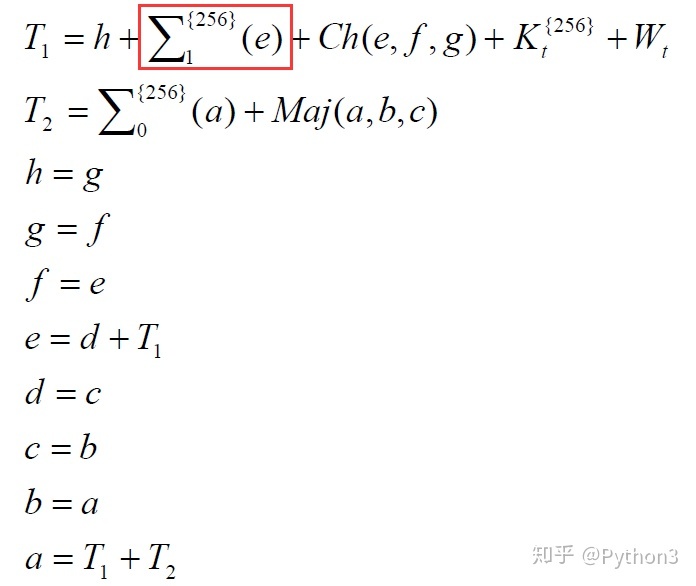
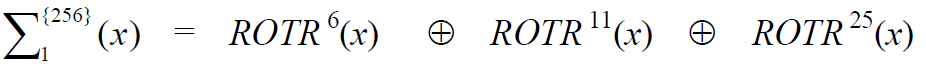
1 | S1 = ROTR(e, 6) ^ ROTR(e, 11) ^ ROTR(e, 25) |
Ch公式分解
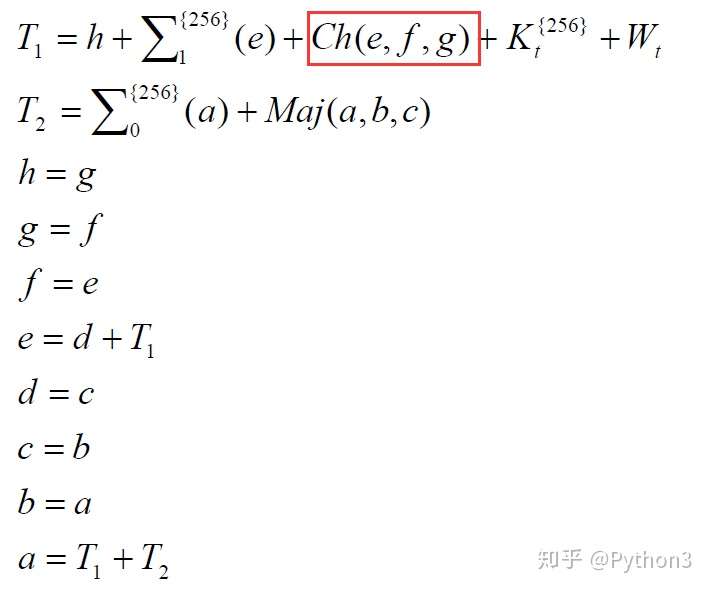
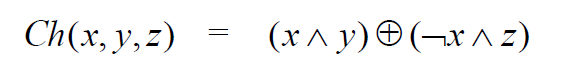
1 | Ch = (e & f) ^ ((~e) & g) |
S0公式分解
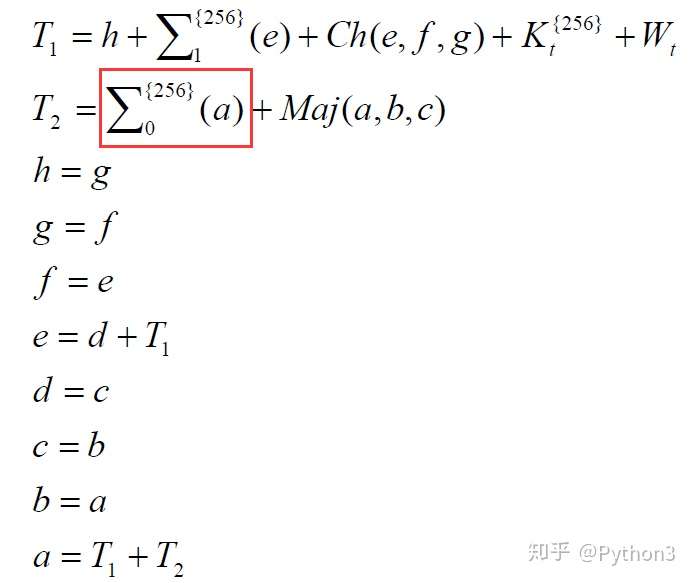
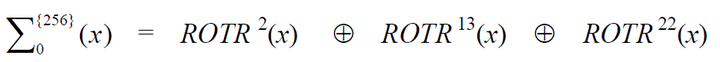
1 | S0 = ROTR(a, 2) ^ ROTR(a, 13) ^ ROTR(a, 22) |
Maj公式分解
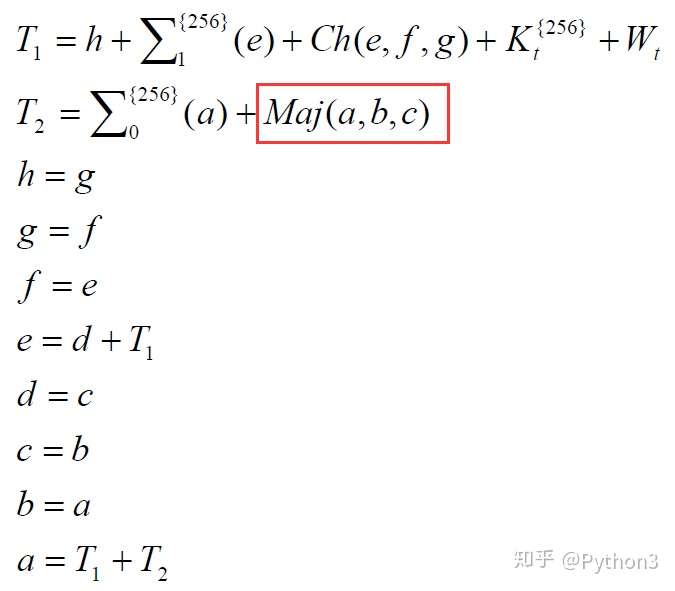
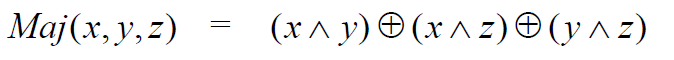
1 | Maj = (a & b) ^ (a & c) ^ (b & c) |
全部整合起来
1 | for t in range(0, 64): |
与初始值H相加

1 | H[0] = a + H[0] & 0xFFFFFFFF |
全部串起来就成了
1 | import hashlib |
DES算法原理
https://github.com/Alex-Yao/DES
聊聊密码学中的DES算法 - 龙跃十二的文章 - 知乎 https://zhuanlan.zhihu.com/p/101573396
DES算法 - flydean的文章 - 知乎 https://zhuanlan.zhihu.com/p/136337280
【密码学】分组密码之DES算法 - 夜煞的文章 - 知乎 https://zhuanlan.zhihu.com/p/461977813
1、参数介绍:
- data(加解密的数据):64bit的明文或者密文需要被加密或被解密的数据
- key(加解密的密钥):8Byte,64bit密钥(56bit密钥+8bit奇偶校验位)
- mode(工作模式):加密或者解密的工作流程
2、工作流程:
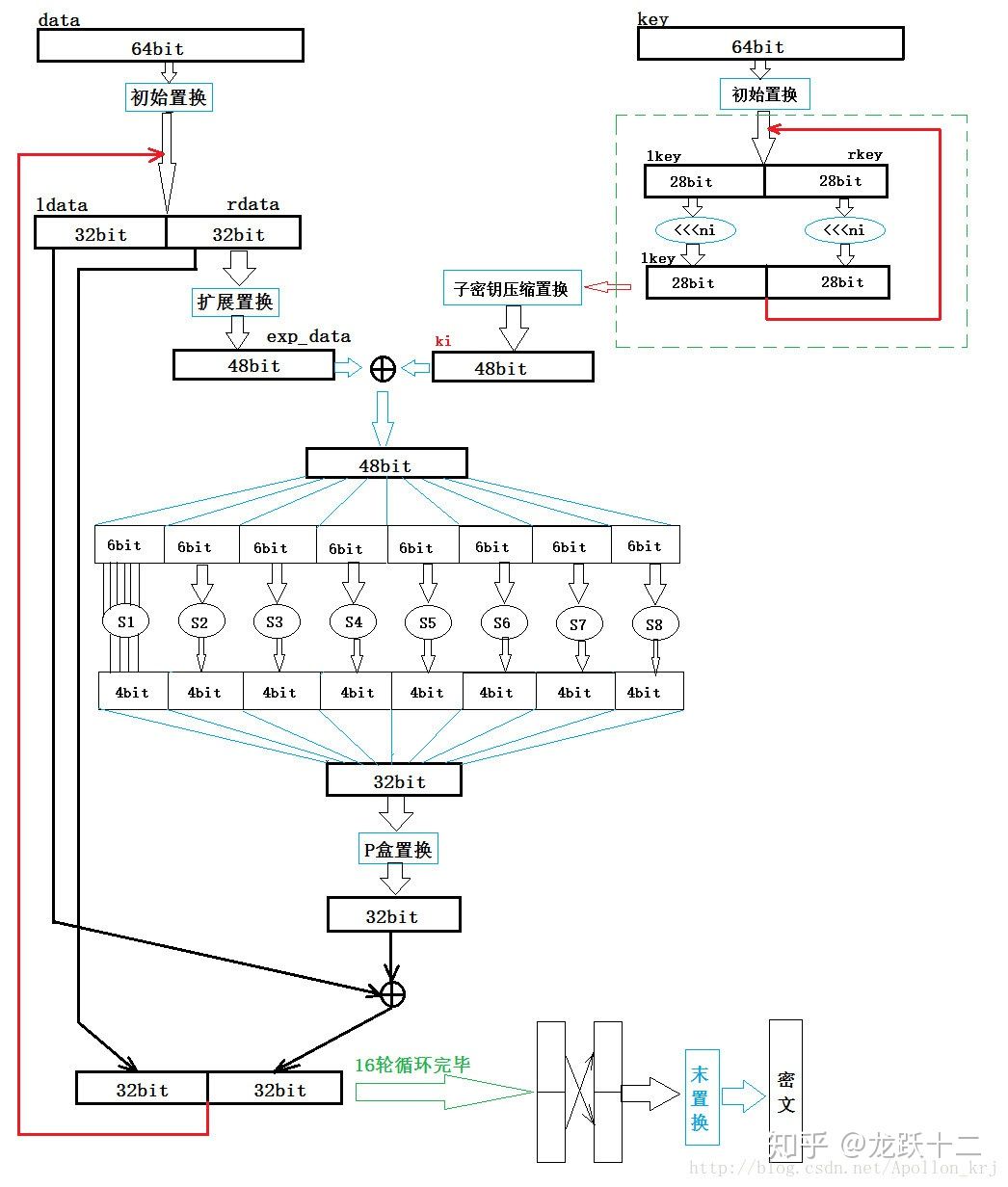
3、初始IP置换:
DES算法使用64位的密钥key将64位的明文输入块变为64位的密文输出块,并把输出块分为L0、R0两部分,每部分均为32位。左部分Li=Ri-1,右部分**Ri=Li-1⊕F(Ri-1,Ki)(注:这里的⊕指二元域上的加法,即异或),初始置换规则如下:
1 | 1 58,50,42,34,26,18,10,02, |
即将输入的64位明文的第1位置换到第40位,第2位置换到第8位,第3位置换到第48位。以此类推,最后一位是原来的第7位。置换规则是规定的。L0是置换后的数据的前32位(D1-D32),R0是置换后的数据的后32位(D33-D64)。
# ------------------进行初始IP置换---------------
for i in range(64):
initTrans[i] = bitText[IP_table[i] - 1]
# 将64位明文分为左右两部分
L = [initTrans[i] for i in range(32)]
R = [initTrans[i] for i in range(32, 64)]
4、轮结构:
F函数是DES的加密核心,作用也是非常大的,而Feistel结构决定了其加密解密流程是相同的,无论是硬件实现还是软件实现都只需要一种结构,不需要分别实现。
函数F由四步运算构成:密钥置换;扩展E变换;S-盒代替;P-盒置换。
密钥置换(子密钥生成)
DES算法由64位密钥产生16轮的48位子密钥。在每一轮的迭代过程中,使用不同的子密钥。
- a、把密钥的奇偶校验位忽略不参与计算,即每个字节的第8位,将64位密钥降至56位,然后根据选择置换PC-1将这56位分成两块C0(28位)和D0(28位);
- b、将C0和D0进行循环左移变化**(注:每轮循环左移的位数由轮数决定)**,变换后生成C1和D1,然后C1和D1合并,并通过选择置换PC-2生成子密钥K1(48位);
- c、C1和D1在次经过循环左移变换,生成C2和D2,然后C2和D2合并,通过选择置换PC-2生成密钥K2(48位);
- d、以此类推,得到K16(48位)。但是最后一轮的左右两部分不交换,而是直接合并在一起R16L16,作为逆置换的输入块。其中循环左移的位数一共是循环左移16次,其中第一次、第二次、第九次、第十六次是循环左移一位,其他都是左移两位。
生成子密钥key
1 | # 生成每一轮的key |
密钥置换
扩展E变换(扩展置换)
扩展E变换是将数据的右半部分Ri从32位扩展到48位。
扩展置换的目的:
- a、产生与密钥相同长度的数据以进行异或运算,R0是32位,子密钥是48位,所以R0要先进行扩展置换之后与子密钥进行异或运算;
- b、提供更长的结果,使得在替代运算时能够进行压缩。
扩展置换E规则如下:
1 | 1 32,01,02,03,04,05, |
也就是说,表中的第i个数据j表示输出的第i位为输入的第j位。例如;输出的第1位是输入的第32位,输出的第7位为输入的第4位。
1 | # -----------进行扩展,将32位扩展为48位-------- |
与子密钥异或
1 | # ----------与key值进行异或运算---------------- |
S盒
S-盒作为feistel结构的核心,起着至关重要的作用。输入的32bit数据经扩展置换之后与48bit子密钥Kn异或,生成的结果作为输入,传入S盒中进行代替运算。S-盒功能是把48位数据变为32位数据,feistel结构中是由8个不同的S盒共同协作完成。其中,每个S-盒有6位输入,4位输出。所以48位的输入块被分成8个6位的分组,每一个分组对应一个S-盒代替操作。经过S-盒代替,形成8个4位分组结果。
注:每一个S-盒的输入数据是6位,输出数据是4位,但是每个S-盒自身是64位!!
S-盒1:
1 | 14,4,13,1,2,15,11,8,3,10,6,12,5,9,0,7, |
S-盒2:
1 | 15,1,8,14,6,11,3,4,9,7,2,13,12,0,5,10, |
S-盒3:
1 | 10,0,9,14,6,3,15,5,1,13,12,7,11,4,2,8, |
S-盒4:
1 | 7,13,14,3,0,6,9,10,1,2,8,5,11,12,4,15, |
S-盒5:
1 | 2,12,4,1,7,10,11,6,8,5,3,15,13,0,14,9, |
S-盒6:
1 | 12,1,10,15,9,2,6,8,0,13,3,4,14,7,5,11, |
S-盒7:
1 | 4,11,2,14,15,0,8,13,3,12,9,7,5,10,6,1, |
S-盒8:
1 | 13,2,8,4,6,15,11,1,10,9,3,14,5,0,12,7, |
S盒的计算:第一位和第六位确定行数,第二、三、四行确定列数,在表中找出对应的数据,将其表示为二进制数据。
1 | # ---------开始进行S盒替换------------------- |
P盒置换
在S-盒代替运算中,每一个S-盒得到4位,8盒共得到32bit输出数据。这32位输出作为P盒置换的输入块,最终输出为32bit的输出数据。P盒置换将每一位输入位映射到输出位。任何一位都不能被映射两次,也不能被略去。
1 | # --------------开始进行P盒置换---------------- |
与ldata数据进行异或
1 | # --------------与L部分的数据进行异或------------ |
5、逆置换:
将初始置换进行16次的迭代,即进行16层的加密变换,这个运算过程我们暂时称为函数f。得到L16和R16,将此作为输入块,进行逆置换得到最终的密文输出块。逆置换是初始置换的逆运算。从初始置换规则中可以看到,原始数据的第1位置换到了第40位,第2位置换到了第8位。则逆置换就是将第40位置换到第1位,第8位置换到第2位。以此类推,逆置换规则如下:
1 | 1 40,08,48,16,56,24,64,32,39,07,47,15,55,23,63,31, |
注:DES算法的加密密钥是根据用户输入的秘钥生成的,该算法把64位密码中的第8位、第16位、第24位、第32位、第40位、第48位、第56位、第64位作为奇偶校验位,在计算密钥时要忽略这8位.所以实际中使用的秘钥有效位是56位。
秘钥共64位,每次置换都不考虑每字节的第8个比特位,这一位是在密钥产生过程中生成的奇偶校验位,所以64位秘钥的第8、16、24、32、40、48、56、64位在计算秘钥时均忽略。
1 | # -----------IP逆置换-------- |
解密过程:
DES的解密过程和DES的加密过程基本类似,唯一的不同是将16轮的子密钥序列的顺序反过来,即在加密过程中所用的加密密钥k1,…,k16在解密过程中需要转换成k16,…,k1。
DES算法整理:
- 分组加密算法:以64bit为分组。输入64bit明文,输出64bit密文。
- 对称算法:加密和解密使用同一秘钥。
- 有效秘钥长度:56bit秘钥,通常表示为64位数,但每个第8位用作奇偶校验,可以忽略。
- 代替和置换:DES算法是两种加密技术的组合:混乱和扩散。
- 易于实现:DES算法只是使用了标准的算术和逻辑运算,其作用的数最多也只有64 位,因此用70年代末期的硬件技术很容易实现算法的重复特性使得它可以非常理想地用在一个专用芯片中。